TypeScriptには、Genericsという機能があります。Genericsは、型をパラメータ化することで型の再利用性を高めるための機能です。
例えば、以下のように関数に<T>という型パラメータを指定することで、関数の引数の型がTであることを示すことができます。
これは、当然JavaScriptには無い機能です。そのため、TypeScriptのパーサは、JavaScriptには無い構文までまとめて解析する必要があります。
ここで厄介なのが、JSXの構文も考慮に入れた時、 TypeScript(TSX)の構文を適切に処理するのは非常に難しい ということです。
例えばTypeScriptで以下のコードを書いた時、私はTypeScriptが<T>を型パラメータとして認識することを意図しています。
しかし、AST ExplorerなどでTypeScriptパーサが生成する抽象構文木(AST)を確認すると、この<T>はGenericsではなくJsxOpeningElement、すなわちJSXの開始タグとして解釈されてしまいます。
これは意図した挙動ではありませんので、このままでは構文エラーになってしまいます。
TypeScriptにこのTが型パラメータであることを正しく解釈させるためには、以下のようにカンマ,を挿入する必要があります。
するとTypeScriptが生成するASTは<T,>をTypeParameterとして解釈し、本来意図した通りになります。
一体なぜでしょうか。
もしも const a = <T>という構文がJSXの文法上正しければ、JSのAutomatic Semicolon Insertion(ASI)により以下のように解釈されたと考えることができます。
しかし、これは正しくありません。JSXの仕様上、JSXの開始タグは対応する終了タグが必要です。そのため、const a = <T>(x: T) => <div>{x}</div>;を意図通りに解釈しない理由に疑問が生じます。
そこで本記事では、TypeScriptのパーサがGenericsをどのように処理しているか、なぜこのような挙動になっているのかについて考えてみたいと思います。
プログラミング言語処理系の入門
TypeScriptのパーサについて考える前に、プログラミング言語の構文がどのように解析されるかについて知っておく必要があります。
本来このテーマだけでも数冊の本が書けるほど奥が深い分野ですが、処理系を厳密に定義するのは本記事の趣旨とは異なるため、ここでは厳密性を犠牲にしてなるべく簡潔かつゆるふわに説明します。
あくまで導入部分だけに留めるため、少しでもかじったことがある方は次章に進んでください。
処理系の流れ
プログラミング言語は通常コンパイラやインタプリタと呼ばれる処理系によって解釈されます。
コンパイラはおおまかに以下のようなフェーズで構成されています。インタプリタは異なる挙動を示すこともありますが、基本的な解析フェーズは共通する部分も多いです。
- 字句解析(Lexical Analysis):ソースコードをトークン(字句)に分割する処理
- 構文解析(Syntax Analysis):トークン列を文法規則に従って解析し、抽象構文木(AST)を生成する処理
- 意味解析(Semantic Analysis):生成されたASTに対して型チェックや変数のスコープ解決などを行う処理
- 中間表現(Intermediate Representation):ASTを中間表現に変換する処理
- 最適化(Optimization):中間表現を最適化する処理
- コード生成(Code Generation):最適化された中間表現から機械語やバイトコードを生成する処理
今回焦点となるのは、この中でも構文解析のフェーズです。
通常プログラムは、文字列で書かれたソースコードとして与えられます。この文字列をトークンに分割する処理が字句解析です。
例えば、以下のようなJavaScriptのコードが与えられたとします。
このコードは、以下のようなトークン列に分割されます。
このようなトークン列を文法規則に従って解析し、抽象構文木(AST)を生成する処理が構文解析です。
構文解析と抽象構文木(AST)
抽象構文木(Abstract Syntax Tree, AST)は、プログラムの構造を木構造で表現したものです。
ESLintのプラグインや、webpack用のプラグインの作成で触れたことがある方も多いかと思います。
例えば、任意のプログラミング言語で書かれた以下のコードが与えられたとします。
このコードは、以下のようなASTに変換されます。
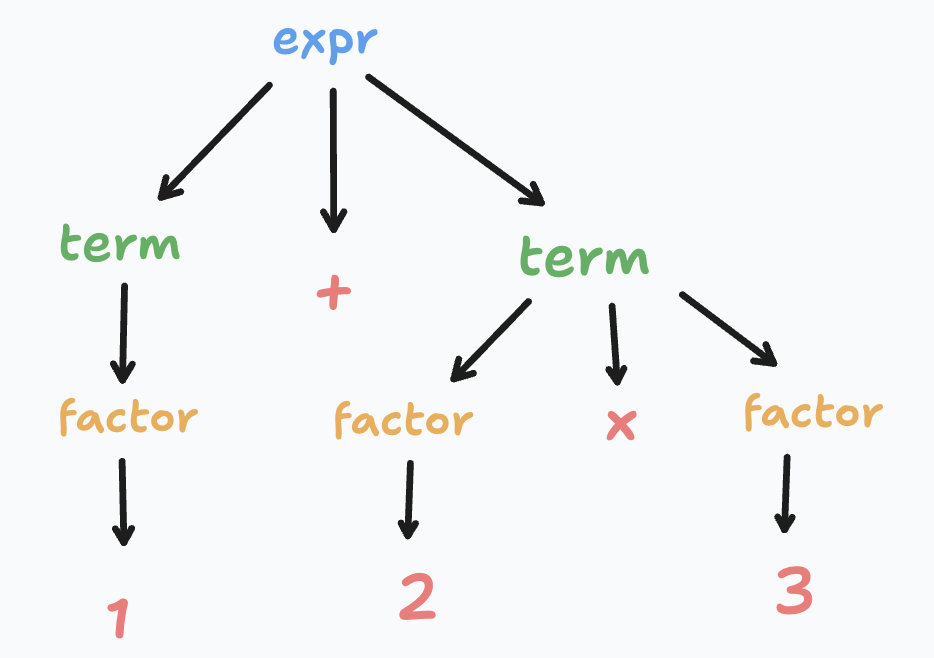
ここで注目して頂きたいのは、演算子の優先順位に基づいて、乗算部分が加算部分よりも一段深い階層になっていることです。
このような構文規則を厳密に定義する方法はいくつかありますが、代表的なものに バッカス・ナウア記法(BNF) があります。
BNFを用いて、上記の例のような四則演算の構文規則を定義すると以下のようになります。
このとき、"0"や"1"などの文字列はこれ以上分解できない最小の単位であるので 終端記号 と呼ばれます。
一方、<式>や<項>などの記号は、終端記号や他の非終端記号に展開されるため 非終端記号 と呼ばれます。
<式>は<式> + <項> or <式> - <項> or <項>に、<項>は<項> * <因子> or <項> / <因子> or <因子>に展開されるため、先ほどの例のように演算子の優先順位を表現することができます。
LL(1)文法と再帰下降パーサ
ここで、アルファベットの大文字を非終端記号、小文字を終端記号として、以下のようなBNFで表現される構文規則があるとします。
この構文規則に従って、仮に文字列abcを入力として受け取ったすると、B ::= b(c | ε)の構文規則に従ってbの後にもしcを選択した場合、abccとなり、入力文字列と一致しません。
一方、空文字εを選択した場合、abcとなり、入力文字列と一致します。
ここでbの後にcを選択して間違いに気づき、一歩手前に戻ってεを選択する手法を バックトラック と呼びます。
「または」のどちらかを選択する際に、バックトラックなしで入力の先端記号を1つ見るだけで選択できる文法を LL(1)文法 と呼びます。
「LL」という名称は「左から右にスキャンする(Left-to-right)」と「最左導出(Leftmost derivation)」を意味し、k文字先を見て選択できる文法を一般にLL(k)と呼びますが、殆どのケースでLLパーサというと単にLL(1)パーサを指していることが多いです。
先ほど例に出した 1 + 2 * 3 という算術式は、LL(1)文法に従って解析することができます。上から順に対応させていくと1は<数>、+は<項>、2は<数>、*は<因子>、3は<数>にそれぞれ1トークン消費するだけで対応付けすることが可能です。
このように、構文規則をトップダウンで全ての非終端記号に対して再帰的に処理する手法を 再帰下降パーサ と呼びます。
厳密には異なりますが、JavaScriptの文法はLL(1)文法に近いため、今回対象となるTypeScriptのパーサも再帰下降で実装されています。
しかし、TypeScriptはJavaScriptの構文に加えて、TypeScript独自の構文を持っているため、1トークン先を見ても選択できない場合が多々あります。
そしてここにJSXも加わると、さらに複雑な構文解析が必要になることは想像に難くありません。
次章では、TypeScriptパーサの実装からその仕組みを探ってみたいと思います。
Deep Dive: TypeScriptパーサ
さて、ここまでで字句解析機(スキャナ)が分解したトークン列を構文解析器(パーサ)がどのように解析して抽象構文木(AST)を生成するかについて説明しました。
それではようやく本題である TypeScriptのパーサがGenerics<T>を特定の状況下でJSXの開始タグとして解釈してしまう理由 について考えてみましょう。
この問題が最初に取り上げられたのは恐らく2017年のGeneric usage reported as JSX ErrorというIssueで、この指摘に対して元TypeScriptチームのEngineering ManagerであるMohamed Hegazy氏は以下のようにコメントしています。
This is a limitation cased by the use of
<T>for generic type parameter declarations. combined with JSX grammar, it makes such components ambiguous to parse.
日本語訳: これは、一般的な型パラメーターの宣言に<T>を使用することによる制限です。JSXの文法と組み合わせると、このようなコンポーネントのパースが曖昧になります。
すなわち冒頭の考察通り、この挙動は仕様として正しいものではなく、パーサがGenerics<T>をJSXの開始タグと識別するのに技術的な制約があるため、このような挙動になっているということが分かります。
この事実を踏まえ、TypeScriptパーサの実装を見てみましょう。実装はTypeScriptのリポジトリから確認することができます。
TypeScriptのパーサは、typescript/src/compiler/parser.tsに実装されています。なんとこのファイル単体だけでも 1万行以上あり非常に膨大ですが、やっていることは先ほど説明した通り、トークン列を構文規則に従って解析し、再帰下降法で抽象構文木(AST)を生成することです。
まずは、パース対象となる文字列として、最初に挙げた以下のコードを例に取り、どのようにParseされるかを確認してみましょう。
このコードがどのようなトークンに分割されるかを確認するため、TypeScriptのスキャナに食わせてみると、概ね以下のようなトークン列に分割されます。(見やすさのため、空白は省略しています。)
これにより、<T> は LessThanTokenとIdentifierおよびGreaterThanTokenとして認識されていることが分かります。
次に、このトークン列をTypeScriptのパーサに食わせて、パーサがどのように解析しているかを確認します。
トークンの先読み
具体的な処理フローの話に入る前に、TypeScriptのパーサがどのように複雑な文法規則を解析しているかについて説明しておきます。
TypeScriptのパーサは1トークン先読みの再帰下降パーサとして実装されていることは先述の通りですが、それではLL(1)で対応できない文法をどのように処理しているのか疑問が生じます。
そのようなケースでは、TypeScriptのパーサは Lookahead という機能を使って、トークンを先読みしてトークンの解釈を決定しています。
TypeScriptでは、parser.tsのParserクラス内に lookAhead というメソッドが実装されており、概念コードとしては以下のように実装されています。
引数にコールバック関数を取り、その関数を実行して結果がfalsyであれば状態を元に戻すという仕組みで、安全にトークンの先読みを行っています。
このような仕組みで、TypeScriptはLL(1)文法に対応できない複雑な文法規則を解析しています。
パーサの解析フロー
ここまでで下準備が整ったので、いよいよTypeScriptパーサの解析フローを見てみましょう。
実際の処理をステップバイステップで追うことは非常に膨大なため、ここでは重要で無いところは駆け足で該当箇所のリンクだけを示し、重要な箇所についてのみ解説を行います。
まず、ソースコードがParserに渡されると、parseSourceFileメソッドが呼び出されます。
この関数はソースコード全体を解析するエントリーポイントで、実際のソースコードの解析はparseSourceFileWorkerメソッドに委譲されます。
今回対象となるconst a = <T>(b: T) => b;は文、すなわちStatementであるため、parseSourceFileWorker内の以下で解析が行われます。
parseStatementにきたタイミングでトークンを読み込みconstを発見し、変数の宣言として判断しparseVariableDeclarationメソッドに処理が委譲されます。
parseVariableDeclarationでは、以下のような形で変数名aを読み込み、=以降に続く右辺の式を解析する処理が行われます。
ここで、parseAssignmentExpressionOrHigherという関数が出てきました。さて、ここから段々今回の肝となる部分に近づいてきます。
このメソッドでは、まず以下のようにして、右辺がアロー関数式であるかどうかを判定します。
tryParseParenthesizedArrowFunctionExpression内部では、トークンが(、<、asyncのいずれかであれば、アロー関数式である可能性があるため、先ほど登場したlookAheadを使って先読みを行い判定します。
我々の手持ちである右辺は<T>(b: T) => bであり、開始トークンは<であるため、この条件式に合致し、lookahead が呼び出されます。
ここで注意したいのは、<T,>(b: T) => bのようにカンマ,を挿入した場合でも、開始タグは<であることには変わりないため、同様にこの条件式に合致し、lookahead が呼び出されます。
ここで呼び出される isParenthesizedArrowFunctionExpressionWorkerこそが、運命の分かれ道 なのです。
このメソッドでは、以下の概念コードに近い形で、トークン先読みを駆使してアロー関数式かどうかを判定しています。
<T に続くトークンが extendsであれば、概ね<T extends {}>のようなジェネリクスであると判断できますし、<T に続くトークンが ,、=であれば、概ね<T,>のようなジェネリクスであると判断できます。
これが、冒頭で述べたようにconst a = <T,>(b: T) => b;が正しく型パラメータとして解釈される理由です。
では、<T>の場合はどうでしょうか。上記コードではどの条件分岐にも引っ掛からず、最終的にreturn falseとなっているということは、トークン先読みで判断できないケースがあるということに他なりません。
次のケースを考えてみましょう。
私自身もテストケースを走らせてみてようやく気づいたのですが。このコードは、正しいJSX構文です。
なぜなら、ここでの() =>は、通常の文字列として解釈可能だからです。このコードは、いわばconst x2 = <T>Hello World</T>と本質的に同じ構造を持っています。
仮にもしここで<T>を型パラメータと判定してしまった場合、後続の () =>という部分はアロー関数式であると判断されてしまうため、後続のJsxClosingElementを正しく解析できなくなります。
このように、2手や3手先のlookaheadでは判断できないケースがあるため、TypeScriptのパーサはアロー関数の型パラメータを、JSXの開始タグとして解釈せざるを得ないのでしょう。
もっと学びたい方へ
駆け足で処理系の基礎からTypeScriptのパーサの仕組みをざっと説明しましたが、もっと勉強してみたいという方向けに、いくつかおすすめの書籍を紹介しておきます。
- Crafting Interpreters: 手を動かすハンズオン形式で処理系の仕組みを学べる。英語だけど無料で読めるのでおすすめ。
- 計算理論の基礎 原著第3版 ①オートマトンと言語: 洋書の翻訳にしては日本語が読みやすい。正規表現と非決定性有限オートマトンの対応が分かって面白かった。
- コンパイラの構成と最適化: 最近買った。全体像の見取り図として使ってる。
感想
人生ではじめてTypeScriptのパーサを読んでみたのですが、意外と読みやすかったです。
ただ、1万行以上あるファイルを読むのは初めての経験で、手元のVSCodeだと数秒に1回ほどのペースで固まってまともに読めず、それが結構大変でした。
Microsfotの専属チームはTypeScriptを開発する時に自社製のVSCodeを使っているのか、それとも別のエディタを使っているのか割と気になっています。
ところで、私はまだ使ったことがありませんが、高速だと噂のEditorにZedというEditorがあります。
ZedはRustで書かれているということで一時期話題になりましたが、個人的に注目しているのはその内部的なアルゴリズムです。
VSCodeは内部的にPiece Tableというデータ構造を使っていることが知られていますが、ZedはPiece Tableではなく Rope というデータ構造を使っているとのことです。
Piece Tableは挿入・削除をO(1)で行うことができる反面、文字列の連結がO(n)かかるという欠点があります。反対に、Ropeは文字列の連結および挿入・削除がO(log n)で行うことができるため、文字列の編集が多い場合にはPiece Tableよりも高速であると言われています。
そこら辺の構造についても興味があるので、今後機会があれば勉強してみたいと思います。
あれ、何の話だっけ。
