This post was originally published in Japanese, but Alex, a friend of mine and the maintainer of Panda CSS suggested it deserves an official English translation. So, here's my attempt at writing an English version of this article.
TypeScript has a feature called Generics, which allows for higher reusability of types by parameterizing them.
For example, you can specify a type parameter <T> in a function to indicate that the type of the function's argument is T:
This is a feature not present in JavaScript. Therefore, TypeScript's parser needs to handle syntax that doesn't exist in JavaScript.
The tricky part is when you mix this with JSX syntax. Handling TypeScript (TSX) syntax correctly becomes very challenging.
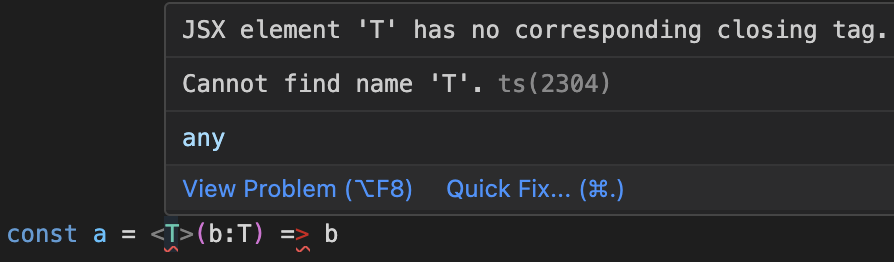
For instance, when you write the following code in TypeScript, you intend for TypeScript to interpret <T> as a type parameter:
However, if you check the Abstract Syntax Tree (AST) generated by the TypeScript parser using tools like AST Explorer, you'll see that <T> is interpreted as JsxOpeningElement, i.e., the opening tag of JSX.
This is not the intended behavior, so it results in a syntax error as follows:
To make TypeScript correctly interpret T as a type parameter, you need to insert a comma , like this:
This way, the TypeScript parser correctly interprets <T,> as a TypeParameter, as intended.
Why is this the case, though?
If the syntax const a = <T> is valid JSX, JavaScript's Automatic Semicolon Insertion (ASI) can interpret it as follows:
However, this is not correct. According to the JSX specification, a JSX opening tag must have a corresponding closing tag. Therefore, the reason why const a = <T>(x: T) => <div>{x}</div>; isn't interpreted as intended raises questions.
In this post, we'll dive into how the TypeScript parser handles Generics and why it behaves this way.
Introduction to Programming Language Processors
Before diving into the TypeScript parser, it's essential to understand how programming language syntax is analyzed.
Although this topic is vast and could fill several books, this post will simplify the explanation to cover only the basics. If you're already familiar with this, feel free to skip to the next section.
Phases of a Compiler
Programming languages are typically interpreted by compilers or interpreters.
A compiler generally consists of the following phases:
- Lexical Analysis: Lexical Analysis
- Syntax Analysis: Parsing the tokens according to grammar rules to generate an Abstract Syntax Tree (AST).
- Semantic Analysis: Performing type checks and resolving variable scopes on the AST.
- Intermediate Representation: Converting the AST to an intermediate representation(IR).
- Optimization: Optimizing the intermediate representation.
- Code Generation: Generating machine code or bytecode from the optimized intermediate representation.
In this post particularly, we'll focus on the Syntax Analysis phase, which involves parsing the token sequence according to grammar rules to generate an AST.
Typically, programs are given as source code in string format. Lexical Analysis breaks this string into tokens.
For example, given the following JavaScript code:
It is broken down into the following tokens:
Syntax analysis parses these tokens according to grammar rules and generates an AST.
Syntax Analysis and Abstract Syntax Tree (AST)
The Abstract Syntax Tree (AST) is a tree representation of the program's structure.
If you've worked with ESLint plugins or webpack plugins, you might be familiar with the concept of AST.
For example, given the following code in any programming language:
This code would be transformed into an AST like this:
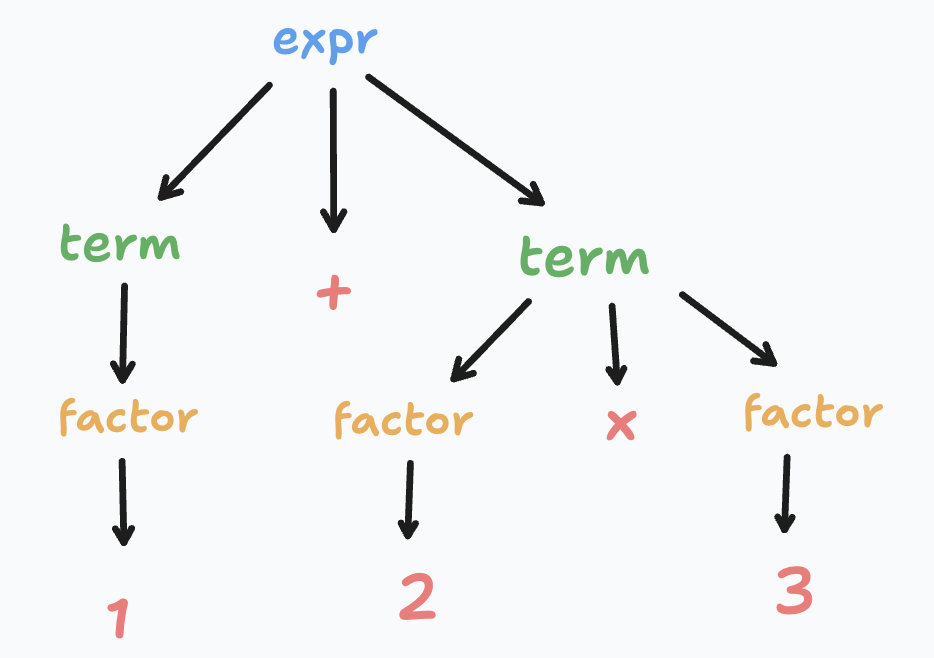
Note that the multiplication part is at a deeper level in the hierarchy compared to the addition part, reflecting operator precedence.
There are several ways to define such grammar rules precisely, with Backus-Naur Form (BNF) being a notable example.
Using BNF, the grammar rules for arithmetic expressions like the one above can be defined as follows:
Here, characters like "0" and "1" are the smallest units that cannot be broken down further, known as terminal symbols.
On the other hand, symbols like <expression> and <term> can be expanded into terminal symbols or other non-terminal symbols, known as non-terminal symbols.
<expression> can be expanded to <expression> + <term> or <expression> - <term> or <term>, and <term> can be expanded to <term> * <factor> or <term> / <factor> or <factor>. This reflects the operator precedence as seen in the example above.
LL(1) Grammar and Recursive Descent Parsering
Consider the following grammar rules expressed in BNF, with uppercase letters as non-terminal symbols and lowercase letters as terminal symbols:
According to these grammar rules, if we input the string abc, and choose b(c) for B, it results in abcc, which does not match the input string. Choosing b(ε) results in abc, which matches the input.
The technique of selecting one option and then reverting to try another if it turns out to be incorrect is known as Backtracking.
Grammars that can be parsed by looking only one token ahead without backtracking are called LL(1) grammars. "LL" stands for "Left-to-right" parsing and "Leftmost derivation".
The arithmetic expression 1 + 2 * 3 mentioned earlier can be parsed according to LL(1) grammar. Each token can be matched one at a time from left to right.
The TypeScript parser, like many JavaScript parsers, is implemented as a recursive descent parser. Recursive descent parsers use recursive functions to process the non-terminal symbols in the grammar rules.
Although JavaScript's grammar is close to LL(1), TypeScript adds its own syntax, making one-token lookahead insufficient in many cases. When JSX is added, the complexity increases further, requiring more sophisticated parsing techniques.
In the next section, we'll delve into the TypeScript parser's implementation to understand how it works.
Deep Dive into TypeScript Parser
Now that we have covered the basic of how the scanner breaks down the token sequence and how the parser analyzes it to generate an AST, let's dive into the main topic: why the TypeScript parser interprets Generics <T> as a JSX opening tag under certain conditions.
This issue was first raised in 2017 in the Generic usage reported as JSX Error issue. Mohamed Hegazy, the former Engineering Manager of the TypeScript team, commented as follows:
This is a limitation caused by the use of
<T>for generic type parameter declarations.
Combined with JSX grammar, it makes such components ambiguous to parse.
In other words, as we considered at the beginning, this behavior is not correct by design. It happens due to the technical constraints of the parser when identifying Generics <T> versus JSX opening tags.
With this understanding, let's look at the implementation of the TypeScript parser. The implementation can be found in the TypeScript repository.
The TypeScript parser is implemented in typescript/src/compiler/parser.ts. This file alone is over 10,000 lines long, and its task is to analyze the token sequence according to grammar rules and generate an AST using the recursive descent parsing.
Let's take the example code we discussed at the beginning and see how it is parsed:
To see how this code is tokenized, we can feed it to the TypeScript scanner, which roughly breaks it down into the following token sequence (spaces are omitted for readability):
This shows that <T> is recognized as LessThanToken, Identifier, and GreaterThanToken.
Next, let's see how the TypeScript parser processes this token sequence.
Token Lookahead
Before diving into the detailed process, let's explain how the TypeScript parser handles complex grammar rules.
As previously mentioned, the TypeScript parser is implemented as a one-token consuming recursive descent parser. However, how does it handle grammars that cannot be parsed with LL(1)?
In such cases, the TypeScript parser uses a technique called Lookahead, which reads tokens ahead and determines their interpretation.
In TypeScript, the lookAhead method is implemented in the Parser class in parser.ts, and the conceptual code looks like this:
By taking a callback function as an argument, executing it, and restoring the state if the result is falsy, this mechanism allows safe token lookahead.
This is how TypeScript handles complex grammar rules that cannot be parsed with LL(1).
Parser Analysis Flow
Now that we've laid the groundwork, let's dive into the flow of the TypeScript parser.
Following each step in detail would be too lengthy, so I'll focus on explaining the key parts and provide links to the relevant sections for more information
First, when the source code is passed to the Parser, the parseSourceFile method is called.
This function is the entry point for parsing the entire source code, and the actual parsing is delegated to the parseSourceFileWorker method.
Since const a = <T>(b: T) => b; is a statement, it's parsed within parseSourceFileWorker using the following:
When parseStatement is called, it reads the tokens, recognizes const, and determines it to be a variable declaration, delegating the process to the parseVariableDeclaration method.
In parseVariableDeclaration, it reads the variable name a and processes the expression on the right side of the =:
Here, the function parseAssignmentExpressionOrHigher comes into play.
This method first checks if the right-hand side is an arrow function expression:
Inside tryParseParenthesizedArrowFunctionExpression, if the token is (, <, or async, it is potentially an arrow function expression, and lookAhead, introduced earlier, is used to determine if it is indeed an arrow function expression.
Since our right-hand side starts with <T>(b: T) => b, it matches the condition and lookAhead is called.
Note that even if we use <T,>(b: T) => b, the initial token < still matches, invoking lookAhead.
The crucial method here is isParenthesizedArrowFunctionExpressionWorker, which determines if the expression is an arrow function using token lookahead:
If the token following <T is extends, it is considered a generic type, and if it is , or =, it is considered a generic type parameter list.
This explains why const a = <T,>(b: T) => b; is correctly interpreted as having a type parameter.
However, what happens with <T>? The above code doesn't cover this case, so it ultimately returns false, meaning it cannot determine the expression by looking ahead a few tokens.
Consider the following case:
I hadn't noticed this until I ran the test cases prepared in the TypeScript repository, but this code is also valid JSX.
In this context, () => can be interpreted as a regular string, making it essentially the same as const x2 = <T>Hello World</T>.
If <T> were mistakenly identified as a type parameter, the () => part would be interpreted as an arrow function, preventing the correct parsing of the subsequent JsxClosingElement.
Thus, due to the limitations of lookahead, the TypeScript parser is forced to interpret the type parameter <T> as a JSX opening tag.
Conclusion
In this post, we delved into the TypeScript parser's implementation to understand why Generics <T> are sometimes misinterpreted as JSX opening tags.
This was my first time reading through the TypeScript parser, and surprisingly, it was quite readable.
However, it was my first experience reading a file with over 10,000 lines, and my VSCode kept freezing every few seconds, making it quite challenging to go through.
I am curious whether the Microsoft's TypeScript team uses a VSCode, which is also a Microsoft product, when developing TypeScript or if they use a different editor.
